
Defining Permissions for Namespaces
HC

Calum Moore
•
Nov 3, 2022

Namespaces
Requirements
Uniquely identify any namespace, collection, record, or field
Prevent spam allocation of namespaces (or people buying many names for resale)
Provide trust by allowing the user to understand ownership
Import code/types from other collections
Compliance with did spec from w3c
Open Questions
How do we (or users) define permissions for namespaces
Namespaces
Namespaces are the fundamental primitive of Polybase. Each namespace can hold a contract, metadata, and permission-based rules. Namespaces are tiered/nested and can have multiple levels of depth:
polybase
polybase/social (child of polybase)
polybase/social/v2 (child of polybase and polybase/social)
Unless a child namespace implements its own controller code, child namespaces inherit the permissions/control defined in their parent. Therefore, by default polybase can add a child namespace polybase/social and have control/permission over it.
Namespaces are defined in a Polybase collection/namespace named polybase/core/ns. The id of this collection is the namespace. polybase/core/ns is the core namespace that is created by the protocol (and is itself included in polybase/core/ns). Namespaces are non-case sensitive, namespaces cannot include spaces.
Each namespace has the following features:
Controller - determining who has control over the namespace and the rules around controlling child namespaces (possibly also code?)
Metadata - data describing attributes of the namespace (could be DNS, email, ENS, etc)
Collection Code - code describing the records that can be stored in this namespace, this may be
Controller Code - code describing the rules related to this namespace and its children
Deploying or updating collections in the namespace (this needs further definition)
Who can define custom metadata for the namespace
Transfer or renounce ownership (allows for contracts to be non-updatable)
Format
Keys on Polybase are globally unique and include namespace, id, and field. Keys on the network will be stored as hashes to maintain privacy.
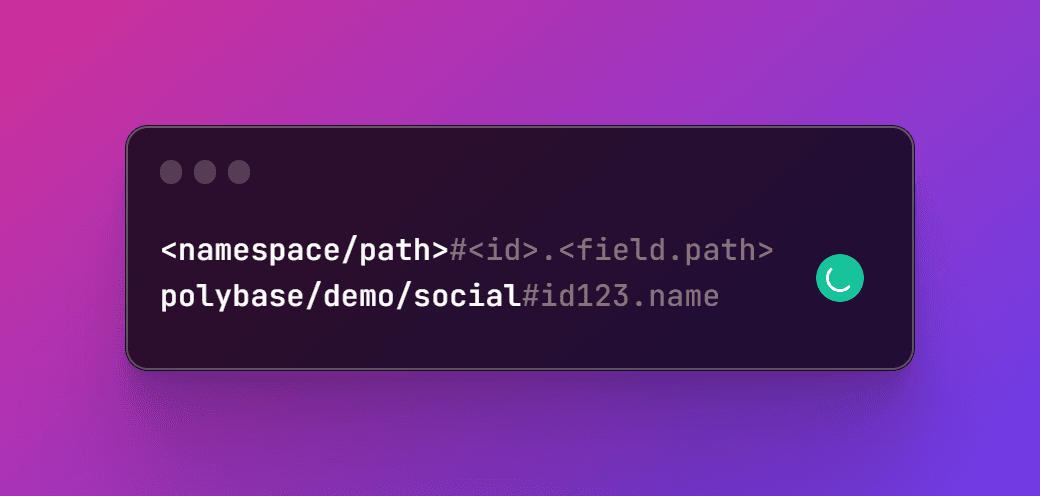
Namespaces are non-case sensitive and cannot include spaces.
Allocation
The problem is that people try to claim lots of names for either spam, fraud, or economic benefit, which damages the experience and usability of the platform. This is particularly important during the initial phase of the project, as many valuable names would be available. For example, someone could claim the Ethereum namespace.
By default, all code will be published to a user's own namespace polybase/core/account/<pk>. All other namespaces will be controlled by Polybase and will be released on request.
Collections
Collections are just namespaces with attached rules on how records can be added, updated, and removed. By default, the user's own namespace polybase/core/account/<pk> will be used to deploy contracts.
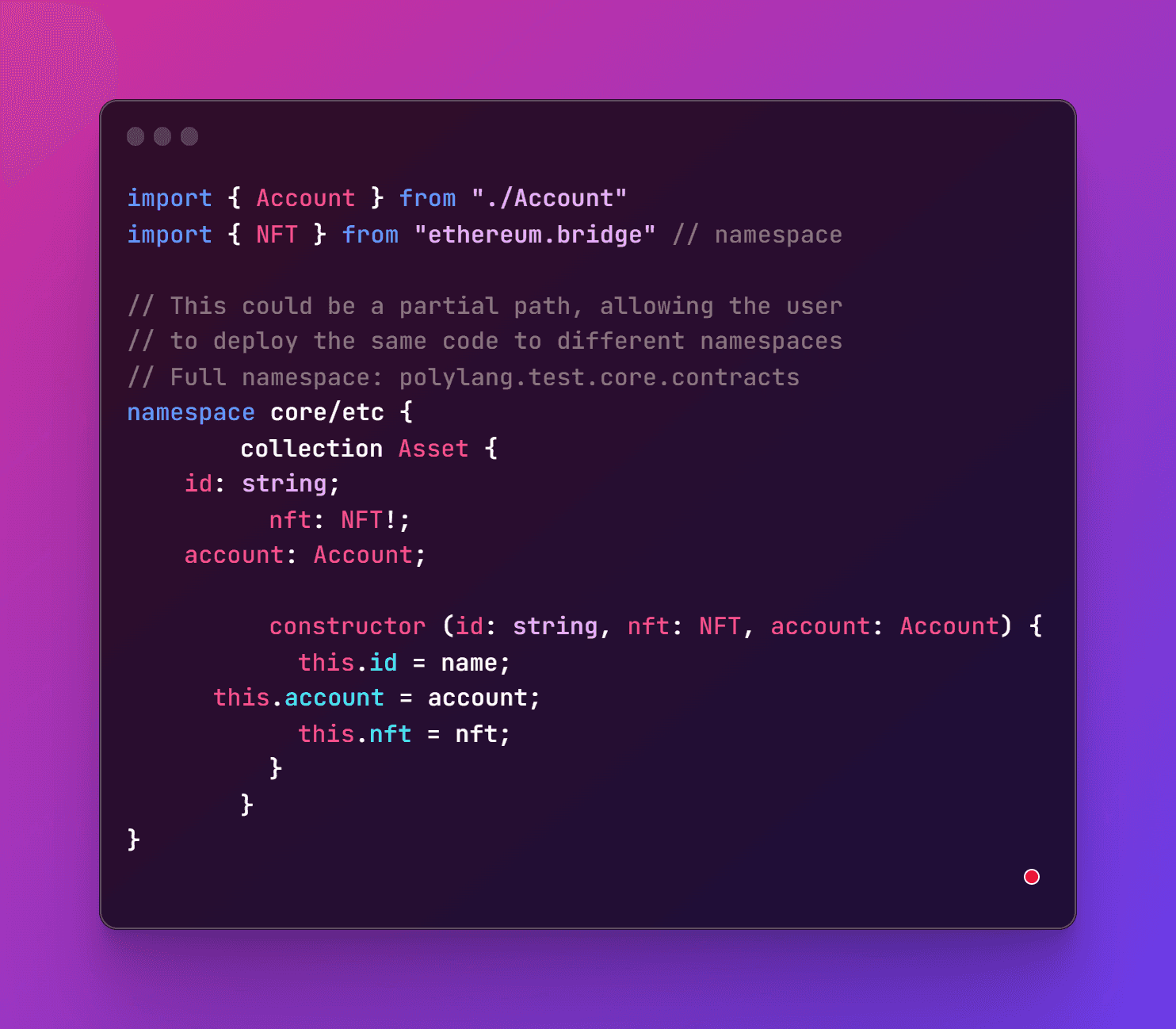
Deploying a contract within a specific namespace
A user could deploy a contract under a specified namespace, and then all codified namespaces would be deployed under that root namespace. The following would result in deployment to the namespace: polybase/test/core/etc/asset:

DIDs
DID infrastructure can be thought of as a global key-value database in which the database is all DID-compatible blockchains, distributed ledgers, or decentralized networks. In this virtual database, the key is a DID, and the value is a DID document.
DID overview
The purpose of the DID document is to describe the public keys, authentication protocols, and service endpoints necessary to bootstrap cryptographically-verifiable interactions with the identified entity (subject or controller).
Defining how a DID and DID document are created, resolved, and managed is the role of a DID method specification. The DID method should define how to perform the following on a DID:
Create
Read
Update
Delete
Some DID methods use blockchains that can store DID documents directly on the blockchain. Others may instruct DID resolvers to construct them dynamically based on attributes of a blockchain record. Still, others may store a pointer on the blockchain to a DID document stored in one or more parts on other decentralized storage networks such as IPFS or STORJ.
Example DID method: https://github.com/zCloak-Network/zk-did-method-specs
Verifiable Credentials
DIDs are only the base layer of decentralized identity infrastructure. The next higher layer – where most of the value is unlocked – is verifiable credentials.
Decentralized IDs are now part of the w3c spec. We can use DIDs for both our namespace and keys.
did:polybase:<hash_of_id>